Everything is an incremental computation
There are some algorithms in computer science that just keep coming up in unrelated domains. There’s one that I see everywhere I look, but never heard described as universal: the algorithm behind incremental computation, reactivity, or change propagation - however you want to call it.
Its most famous implementation is the one that powers spreadsheets like Excel. If you have a large sheet with many formulas and the value of one cell changes, how do you propagate that change in the most efficient manner?
The base of the algorithm is always the same. You maintain a computation graph that allows you to answer two questions:
- Observers: for each node (= spreadsheet cell), who depends on it?
- Dependencies: for each node, on whom does it depend?
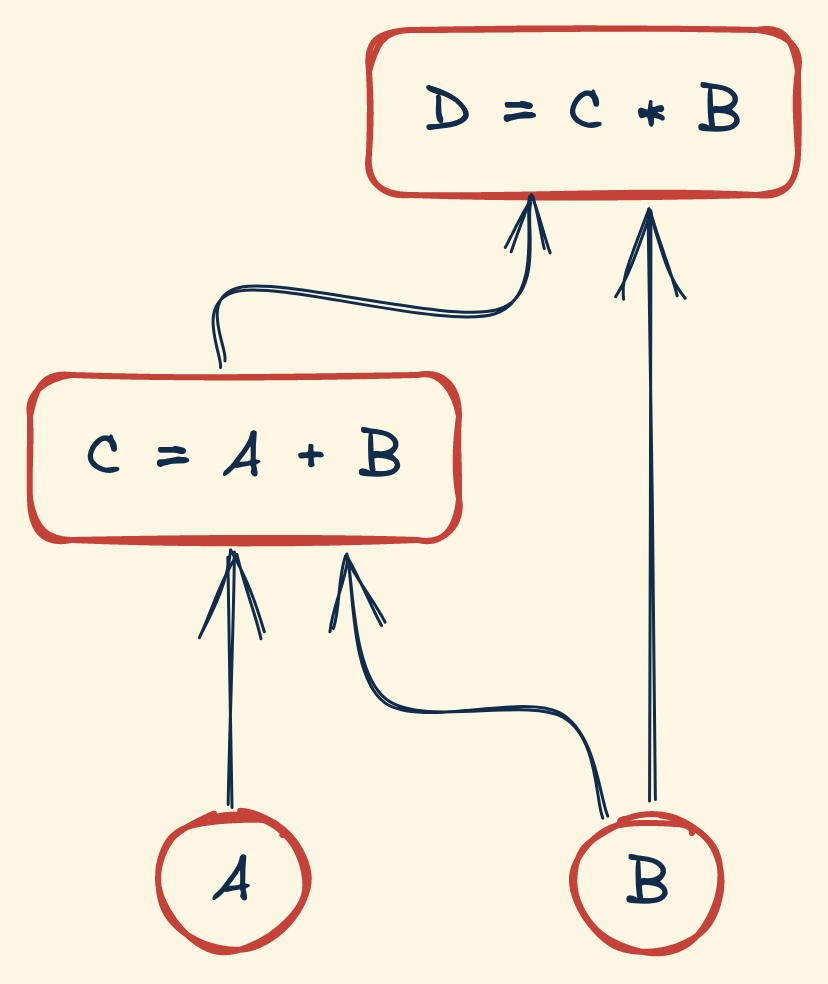
With such a visual representation, you can probably see that if B changes, we should first recompute C and then recompute D (and not the other way around). On the other hand, if we change D’s formula, we can update its value without recomputing C.
I won’t go into more details regarding the algorithm, but if you’re interested to learn how performant implementations work, I recommend the excellent How to recalculate a spreadsheet.
Incrementalising all the things
While spreadsheets are the most well known example, this technique is used everywhere:
- Reactive UI frameworks like Vue, Svelte, Solid, Knockout, etc…
- Build systems and incremental compilation
- Financial applications
- Incremental queries in databases
- 2D/3D rendering
After all, the purpose of all programs is simply to transform data from one form to another. All examples above do exactly that, whether they are outputting HTML, compiled programs, financial analytics, SQL query results or graphics.
And at some point, the input data will change. Generally, only a fraction of the input changes, so how do we update the output without recomputing everything from scratch? This is exactly the problem of incremental computation.
Framing the problem this way is also incredibly liberating for designing programs: for any non-trivial computation, it’s much easier to write how to do something from scratch than how to precisely update the output based on any possible change of the input. Being able to automate the update process allows you to just “write the spec” and get an efficient program out of it.
Compile the update path
Converting a regular computation into an incremental one is essentially a compiler problem. Existing approaches take different forms:
- Runtime compilers, which track which values are accessed during a computation (Solid, the Rust compiler).
- “Structured” compilers, where a library forces you to write your computations in a constrained way to optimise them (Incremental or differential dataflow).
- Classical compilers, which can either reuse syntax from their target language (Svelte, Vue) or implement a completely new language for incremental computation (Skip, Fungi).
UIs, programming languages and distributed systems
I think this paradigm is just starting to be embraced and we have barely seen its consequences.
The modern version of the change propagation algorithm has been formalised in academic research around 2014, with Adapton. That’s very new!
Just in the past few years, we’ve seen new approaches appear in multiple domains as a result of the wider adoption of efficient incremental computation.
In the web UI world, Solid redefined just how efficient JavaScript frameworks can be: it’s a 6kB library, nearly as fast as carefully hand-optimised JavaScript code, with advanced features that barely exist in other frameworks. In the same vein, Svelte is becoming famous for its simple syntax, where everything “just works” and the compiler takes care of inserting all the incremental update mechanisms, ensuring your UI is always in sync with your data.
In programming languages, Rust was the first major compiler to adopt an incremental computation framework for demand-driven compilation. It also enabled IDE tooling like rust-analyzer to reuse this approach to improve its performance and analysis, as it attempts to provide instantaneous feedback while you are typing in your editor.
Incremental view maintenance, from the database to the UI
An area I’m especially interested in is building offline + collaborative applications. It’s a hard problem, which can be solved using conflict-free replicated data types (CRDTs): they are data structures that provide automatic synchronisation & conflict resolution, while being robust to extended periods of offline work.
They are also notoriously hard to implement efficiently. In practice, the problem often boils down to: “how do I efficiently insert this new operation into the existing state?”. That sounds suspiciously like an incremental update...
One of the clearest ways to define CRDTs is as a query over a set of operations. This model makes synchronisation trivial, leaving only the need to define conflict resolution semantics. It was also the first to introduce a CRDT operation for moving elements in a tree. Its theoretical simplicity makes it a great foundation for building more complex or domain-specific data types. However, the model provides no way to efficiently update the CRDT query when a new operation comes in. Wait a second, that's definitely an incremental computation problem!
If we were able to define this model in a language or framework that automatically provides incremental updates for queries, then we could just define the spec for a CRDT and get an efficient implementation for free!
Combine this with another idea: a UI is just a function of data. There is an initial render (= query over the data), then incremental updates as the underlying data changes (= incremental computation).
This is the same setup as replicated data types and both are just a view into the underlying data: the CRDT is a view of a set of operations, the UI is a view of the base application state.
Going further, maybe the two could be expressed in a single query language, given a suitable query language (not SQL). Then, the whole application stack could be expressed a single incremental query over local data, which syncs automatically across the network. In that paradigm, the data is unified in a single logical place, simplifying the mental model by eliminating all concerns around stale data or synchronisation.
Everything is an incremental query
I suspect nearly all programs could be expressed in this paradigm of (sidenote: A popular saying is that all computer science problems are either a compiler or a database. Query = database + compiler, incremental updates = compiler, so I guess this fits. ) What we, as developers, want to write is the “from scratch” computation, the query. Efficient updates should be handled by a compiler, to spare us both the effort and the incredible amount of bugs that comes with handmade implementations.
More than that, incremental computation is not just a performance gain: the affordances it creates radically change the ways you can think about a problem.
Once you are freed of the complexity of efficiently maintaining some output, you can start building new architectures you would not have dared to dream about before.